library(igraph)
library(netrankr)
library(networkdata)4 Centrality
Centrality is one of the most fundamental concepts in network analysis. It provides a way to quantify the importance or prominence of individual nodes within a network. In social networks, centrality helps answer questions like: Who is the most influential person? Who controls the flow of information? Who can reach others most efficiently? There is no single answer to “who is most central” because importance depends on the structural feature we consider relevant. This chapter introduces the most commonly used centrality indices, discusses their interpretation, and demonstrates how to compute them in R.
4.1 Packages Needed for this Chapter
4.2 What Is Centrality?
At its core, a centrality index assigns a numeric value to each node in a network. Higher values indicate greater centrality, but what “central” means depends on the index. Different indices capture fundamentally different notions of importance, each tied to a different structural property of the network. The four most widely used families of centrality, formalized in the conceptual clarification of Freeman (1979), can be mapped to distinct social intuitions:
- Degree measures activity: How many direct connections does a node have? A node with many ties is active, popular, or well-connected.
- Closeness measures efficiency: How quickly can a node reach all others? A node that is close to everyone can spread information or access resources with minimal steps.
- Betweenness measures brokerage: How often does a node sit on the shortest path between others? A node with high betweenness controls or mediates the flow between other parts of the network.
- Eigenvector centrality measures prestige: Is a node connected to other well-connected nodes? A node may have few ties, but if those ties are to important nodes, it is central by association.
These four intuitions are not interchangeable. A broker (high betweenness) need not be popular (high degree), and a prestigious node (high eigenvector) need not be efficient at reaching everyone (high closeness). This is precisely why multiple indices exist and why the choice of index should be guided by the research question at hand. Dozens of further indices have been proposed, most of which refine or combine these four ideas. We include one such example below, namely subgraph centrality, which captures local embeddedness via closed walks of all lengths, to give a flavor of what lies beyond the four main families.
Note
For a more formal treatment of what constitutes a centrality index and the structural properties that underlie different indices, see Section 4.10.
4.3 Centrality Indices in igraph
The igraph package implements a broad range of centrality indices. To illustrate them, we use the dbces11 graph from the netrankr package, shown in Figure 4.1. This small network is useful because different indices disagree on which node is most central, making the distinctions between indices visible.
data("dbces11")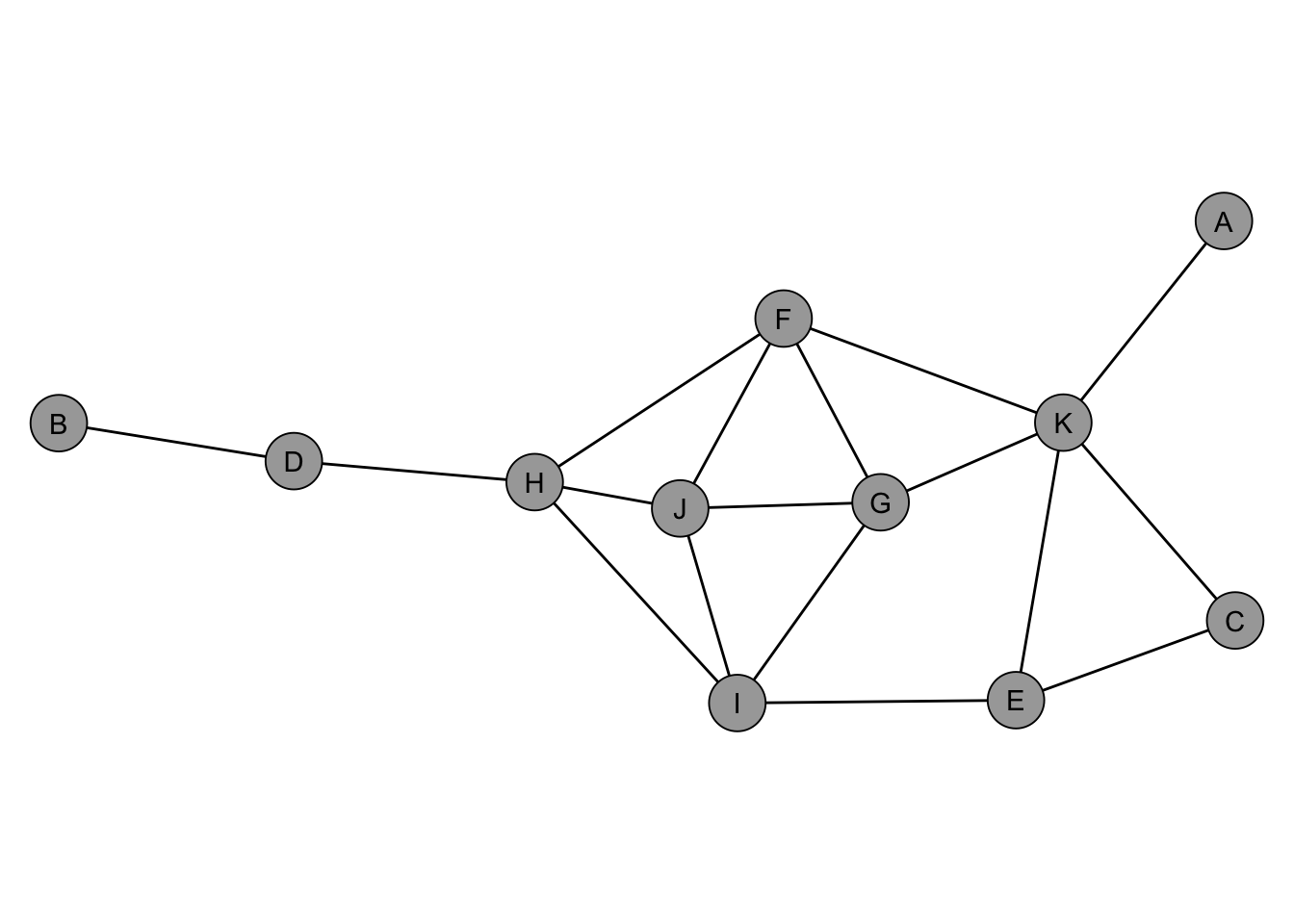
4.3.1 Degree
The most straightforward centrality index is degree, which counts the number of neighbors a node has. A node with high degree is directly connected to many others, making it active or popular in a social sense. Formally, letting \(A = (a_{vu})\) denote the adjacency matrix,
\[ C_D(v) = \sum_{u \neq v} a_{vu}. \]
degree(dbces11)A B C D E F G H I J K
1 1 2 2 3 4 4 4 4 4 5 For weighted networks, strength (also called weighted degree) sums the edge weights instead of counting ties. This is useful when ties carry different intensities, such as frequency of communication or volume of trade. As an illustration we use the miserables network, which records co-occurrences of characters in Victor Hugo’s Les Misérables, with edge weights counting how often two characters appear in the same chapter.
data("miserables")
head(sort(
strength(miserables, weights = E(miserables)$weight),
decreasing = TRUE
)) Valjean Marius Enjolras Courfeyrac Cosette
158 104 91 84 68
Combeferre
68 4.3.2 Closeness
Closeness centrality is based on the shortest path distances between nodes. The idea is that a central node can reach all other nodes quickly. Letting \(d(v, u)\) denote the length of the shortest path from \(v\) to \(u\),
\[ C_C(v) = \frac{1}{\sum_{u \neq v} d(v, u)}, \]
so that nodes with shorter total distances receive higher scores.
closeness(dbces11) A B C D E
0.03703704 0.02941176 0.04000000 0.04000000 0.05000000
F G H I J
0.05882353 0.05263158 0.05555556 0.05555556 0.05263158
K
0.05555556
Tip
Closeness centrality is only well-defined for connected networks, since distances between disconnected components are infinite. igraph::closeness() computes the score over the reachable nodes only and returns NaN for isolates, so the result can still be interpreted but ranks across components are not strictly comparable. A cleaner alternative is igraph::harmonic_centrality(), which defines centrality as the sum of inverse distances (treating unreachable pairs as zero contribution) and handles disconnected networks without special casing.
4.3.3 Betweenness
Betweenness centrality counts how often a node lies on the shortest path between pairs of other nodes. A node with high betweenness acts as a bridge or broker: removing it would increase distances or disconnect parts of the network. Letting \(\sigma_{st}\) denote the number of shortest paths from \(s\) to \(t\) and \(\sigma_{st}(v)\) the number of those passing through \(v\),
\[ C_B(v) = \sum_{s \neq v \neq t} \frac{\sigma_{st}(v)}{\sigma_{st}}. \]
betweenness(dbces11) A B C D E F
0.000000 0.000000 0.000000 9.000000 3.833333 9.833333
G H I J K
2.666667 16.333333 7.333333 1.333333 14.666667 4.3.4 Eigenvector Centrality
Eigenvector centrality (Bonacich 1987) extends the idea of degree by weighting each connection by the centrality of the neighbor. A node is central if it is connected to other central nodes, which leads to the recursive definition
\[ C_E(v) = \frac{1}{\lambda} \sum_{u \in N(v)} C_E(u), \]
where \(\lambda\) is the leading eigenvalue of the adjacency matrix. The vector of scores is the corresponding leading eigenvector.
eigen_centrality(dbces11)$vector A B C D E F
0.2259630 0.0645825 0.3786244 0.2415182 0.5709057 0.9846544
G H I J K
1.0000000 0.8386195 0.9113529 0.9986474 0.8450304
Tip
On disconnected networks, the leading eigenvector of the adjacency matrix concentrates on a single connected component (the one with the largest leading eigenvalue), and nodes in other components receive scores close to zero. The resulting ranking is therefore only meaningful within a single component; for cross-component comparisons, restrict the analysis to the largest component first.
4.3.5 Subgraph Centrality
Subgraph centrality (Estrada and Rodriguez-Velazquez 2005) quantifies the participation of each node in all subgraphs of the network, weighted by the inverse factorial of their size. It captures how embedded a node is in the local structure of the network, counting closed walks of all lengths.
subgraph_centrality(dbces11) A B C D E F G
1.825100 1.595400 3.148571 2.423091 4.387127 7.807257 7.939410
H I J K
6.672783 7.032672 8.242124 7.389559 4.3.6 Comparing Indices
Figure 4.2 shows the most central node according to each of the indices computed above. Each index picks a different node as most central, highlighting how the choice of index determines what we consider “important.”
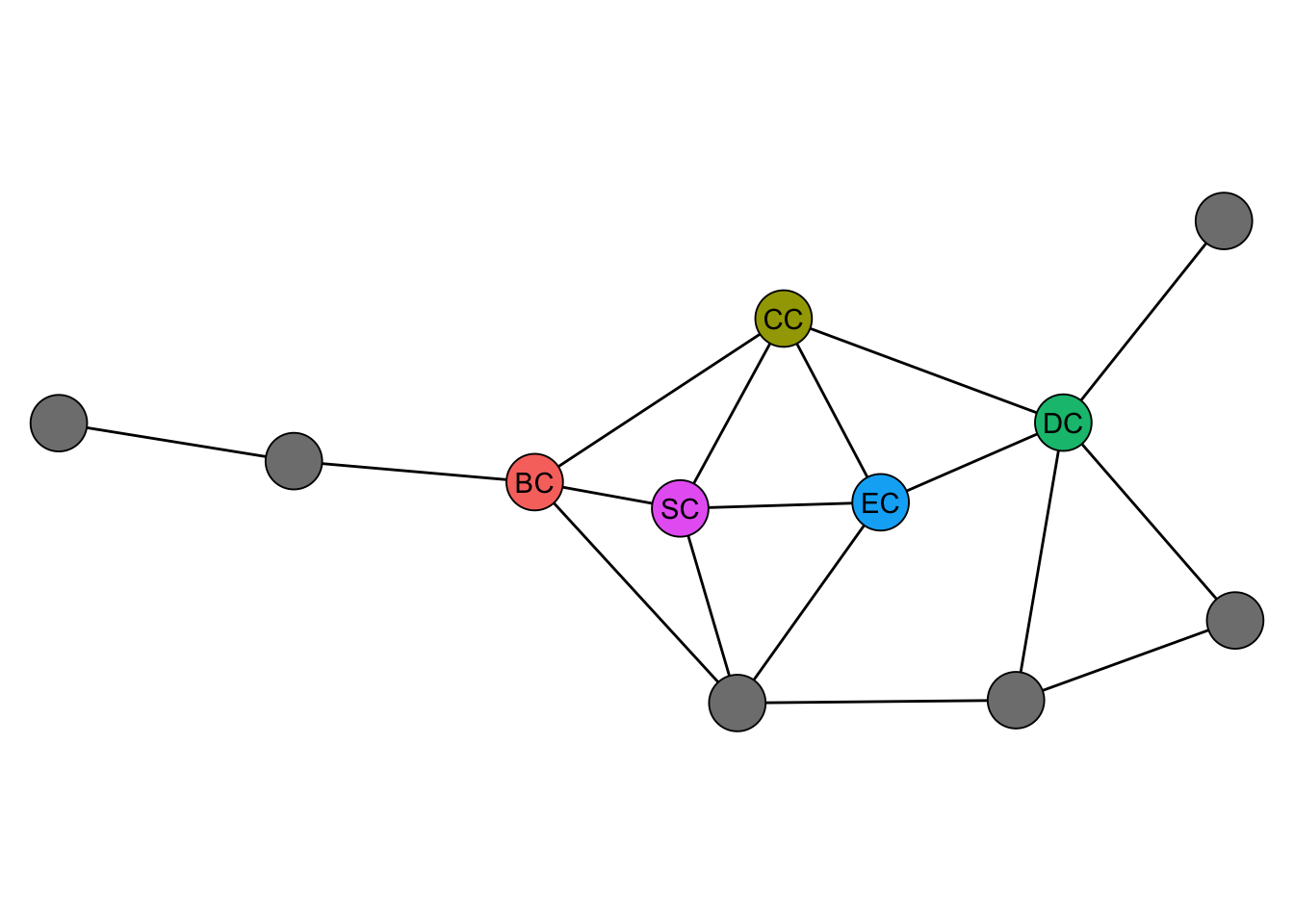
While this is a toy example, it illustrates an important point: centrality indices can produce substantially different rankings. In empirical settings, this means the choice of index is consequential and should be driven by the research question rather than convenience.
The dbces11 comparison above tells us which node each index picks as most central, but not how the indices track each other across the full ranking. To see that, we move from the toy example to a realistic network and examine the pairwise correlations of the scores.
4.3.7 Correlation Between Indices
On some networks, all indices will largely agree; on others, they will diverge considerably. We examine this using Zachary’s karate club network, a classic social network of 34 members of a university karate club observed over three years in the 1970s.
data("karate")cent_df <- data.frame(
degree = degree(karate),
closeness = closeness(karate),
betweenness = betweenness(karate),
eigen = eigen_centrality(karate)$vector
)
round(cor(cent_df), 2) degree closeness betweenness eigen
degree 1.00 0.77 0.91 0.92
closeness 0.77 1.00 0.72 0.90
betweenness 0.91 0.72 1.00 0.80
eigen 0.92 0.90 0.80 1.00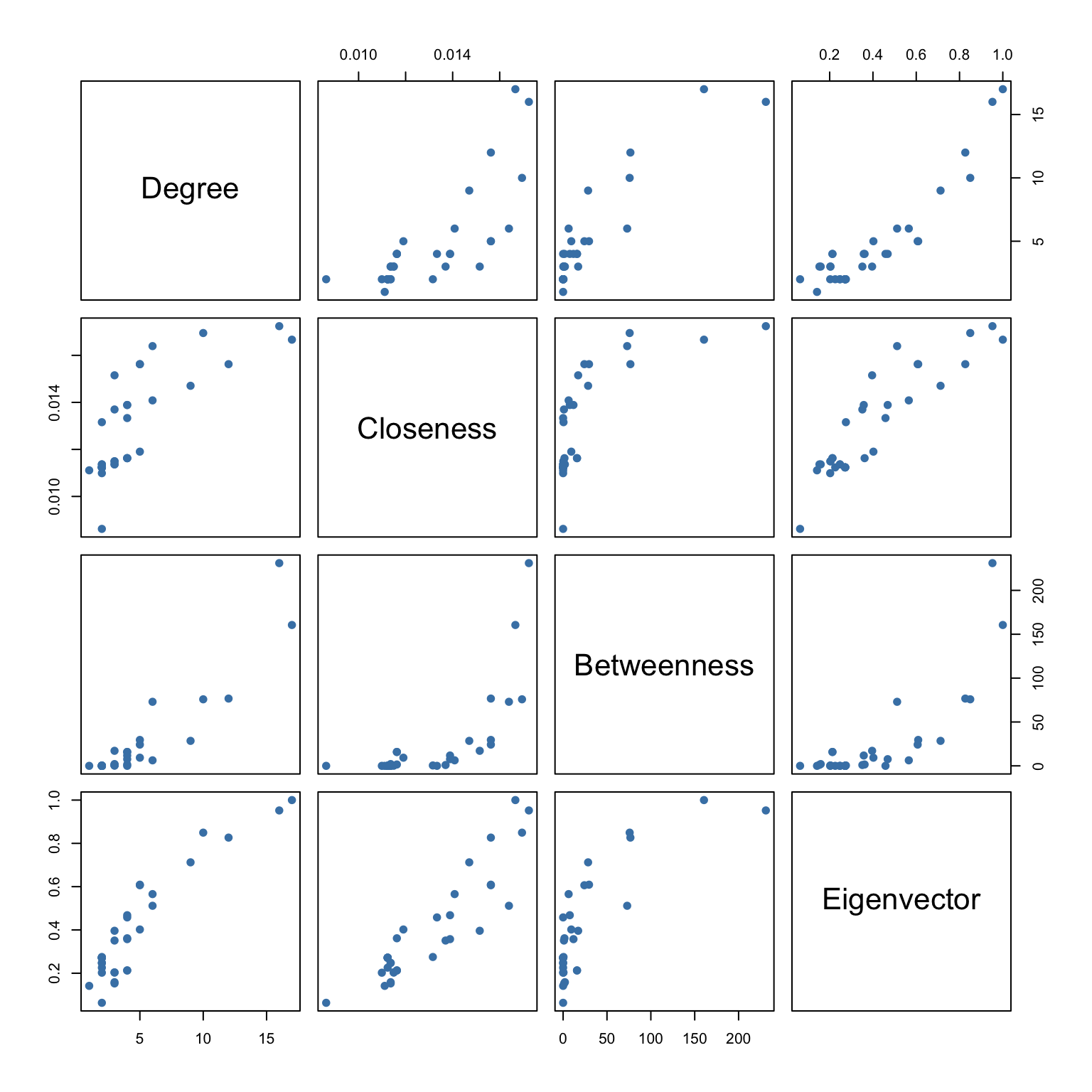
The correlation matrix and the pairwise scatter plots in Figure 4.3 reveal which indices capture similar information and where they diverge. High correlations (e.g., between degree and eigenvector centrality) suggest that the structural features they measure overlap in this network, while low correlations indicate genuinely different dimensions of centrality.
4.4 Directed Networks
The indices introduced so far treat every tie symmetrically. In many social networks, however, the direction of a tie carries meaning: who asks whom for advice, who endorses whom, who follows whom. A handful of centrality indices are designed specifically for directed networks and distinguish between a node’s incoming and outgoing ties.
To illustrate them, we use the ht_advice network, a classic study of advice-seeking relations in a small high-tech company. A directed edge from i to j indicates that employee i sought advice from j.
data("ht_advice")4.4.1 PageRank
PageRank (Brin and Page 1998) is perhaps the best-known index for directed networks, originally developed to rank web pages. It assigns each node a score that grows with the number and the PageRank of its incoming neighbors. In a social setting, a high PageRank identifies individuals who receive attention or endorsement from other well-regarded individuals.
round(page_rank(ht_advice)$vector, 3) [1] 0.049 0.094 0.027 0.046 0.016 0.072 0.104 0.042 0.015 0.030
[11] 0.039 0.040 0.014 0.044 0.016 0.028 0.042 0.072 0.014 0.033
[21] 0.1644.4.3 Use Case: Ranking Tennis Players
PageRank was originally designed to rank web pages, but the same logic applies to any directed network in which an incoming edge can be read as an endorsement. Professional tennis is a natural fit. Every match produces a directed tie from the losing player to the winner, so a season of matches induces a directed network in which a node accumulates incoming edges from the opponents it has beaten. Counting wins gives a first approximation of player strength (the in-degree), but PageRank refines this by weighting each win by the standing of the defeated opponent. A player who beats other strong players is rewarded more than a player who accumulates wins against weaker opponents, which is closer to how strength is judged informally in the sport.
The networkdata package provides season-level networks for the men’s (atp) and women’s (wta) tours from 1968 to 2021, with each list element representing one season. Edges point from loser to winner, and the edge weight records how many times that match-up occurred on a given surface. To rank players across the entire history of each tour, we collapse all 54 seasonal networks into a single weighted directed network: the weight of an edge from player i to player j is the total number of matches i lost to j over the period 1968-2021.
data(atp)
data(wta)combine_seasons <- function(net_list) {
edges <- do.call(
rbind,
lapply(net_list, function(g) {
igraph::as_data_frame(g, what = "edges")[, c("from", "to", "weight")]
})
)
edges <- aggregate(weight ~ from + to, data = edges, FUN = sum)
graph_from_data_frame(edges, directed = TRUE)
}
atp_all <- combine_seasons(atp)
wta_all <- combine_seasons(wta)
atp_allIGRAPH e9d55e3 DNW- 5965 118906 --
+ attr: name (v/c), weight (e/n)
+ edges from e9d55e3 (vertex names):
[1] Jan Kukal ->A Macdonald
[2] Alberto Tous ->Aaron Krickstein
[3] Alejandro Ganzabal->Aaron Krickstein
[4] Alex Antonitsch ->Aaron Krickstein
[5] Alex Obrien ->Aaron Krickstein
[6] Alexander Mronz ->Aaron Krickstein
[7] Alexander Reichel ->Aaron Krickstein
[8] Alexander Volkov ->Aaron Krickstein
+ ... omitted several edgeswta_allIGRAPH 58fe8e9 DNW- 5946 88958 --
+ attr: name (v/c), weight (e/n)
+ edges from 58fe8e9 (vertex names):
[1] Urszula Nebelska ->Aaliya Ebrahim
[2] Alexandra Damaschin->Abbie Myers
[3] Alison Bai ->Abbie Myers
[4] Ayano Shimizu ->Abbie Myers
[5] Claire Liu ->Abbie Myers
[6] Erina Hayashi ->Abbie Myers
[7] Francesca Jones ->Abbie Myers
[8] Irina Maria Bara ->Abbie Myers
+ ... omitted several edgesThe combined networks are large, with several thousand players and over a hundred thousand directed match outcomes between them. We compute PageRank on each network and inspect the ten highest-scoring players.
atp_pr <- page_rank(atp_all)$vector
wta_pr <- page_rank(wta_all)$vector
round(head(sort(atp_pr, decreasing = TRUE), 10), 4) Roger Federer Jimmy Connors Novak Djokovic Rafael Nadal
0.0076 0.0072 0.0066 0.0065
Ivan Lendl John Mcenroe Guillermo Vilas Ilie Nastase
0.0065 0.0054 0.0049 0.0047
Andre Agassi Stefan Edberg
0.0046 0.0044 round(head(sort(wta_pr, decreasing = TRUE), 10), 4) Martina Navratilova Chris Evert
0.0117 0.0084
Steffi Graf Serena Williams
0.0084 0.0073
Venus Williams Arantxa Sanchez Vicario
0.0064 0.0057
Lindsay Davenport Monica Seles
0.0054 0.0053
Gabriela Sabatini Martina Hingis
0.0051 0.0050 Figure 4.4 and Figure 4.5 visualize the subnetworks induced by the 50 highest-ranked players on each tour, with node size proportional to PageRank and labels for the top twelve. The dense pattern of edges among these nodes reflects how often elite players meet one another, and this concentration is what makes PageRank meaningful: the score of a top player is determined almost entirely by results within this small clique.
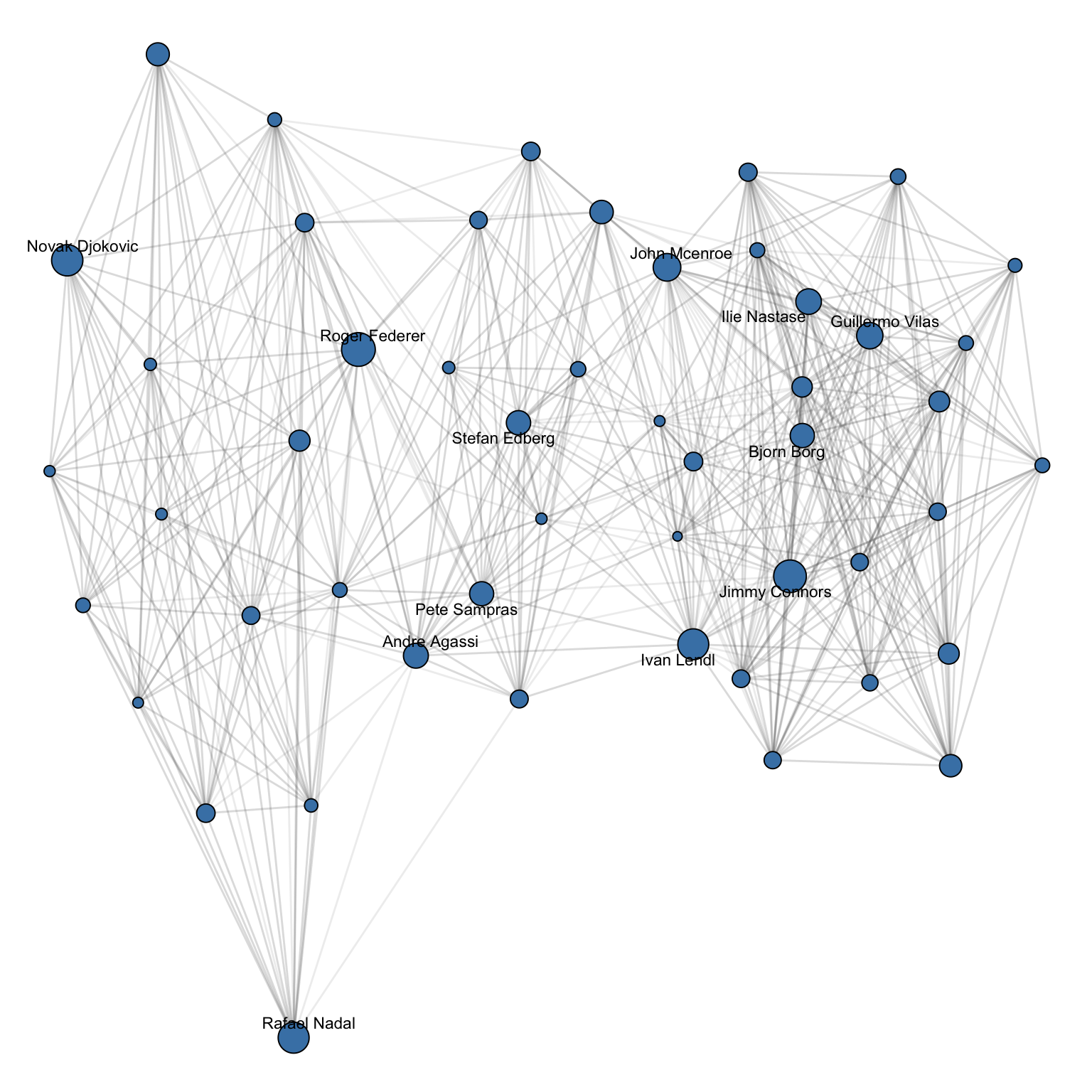
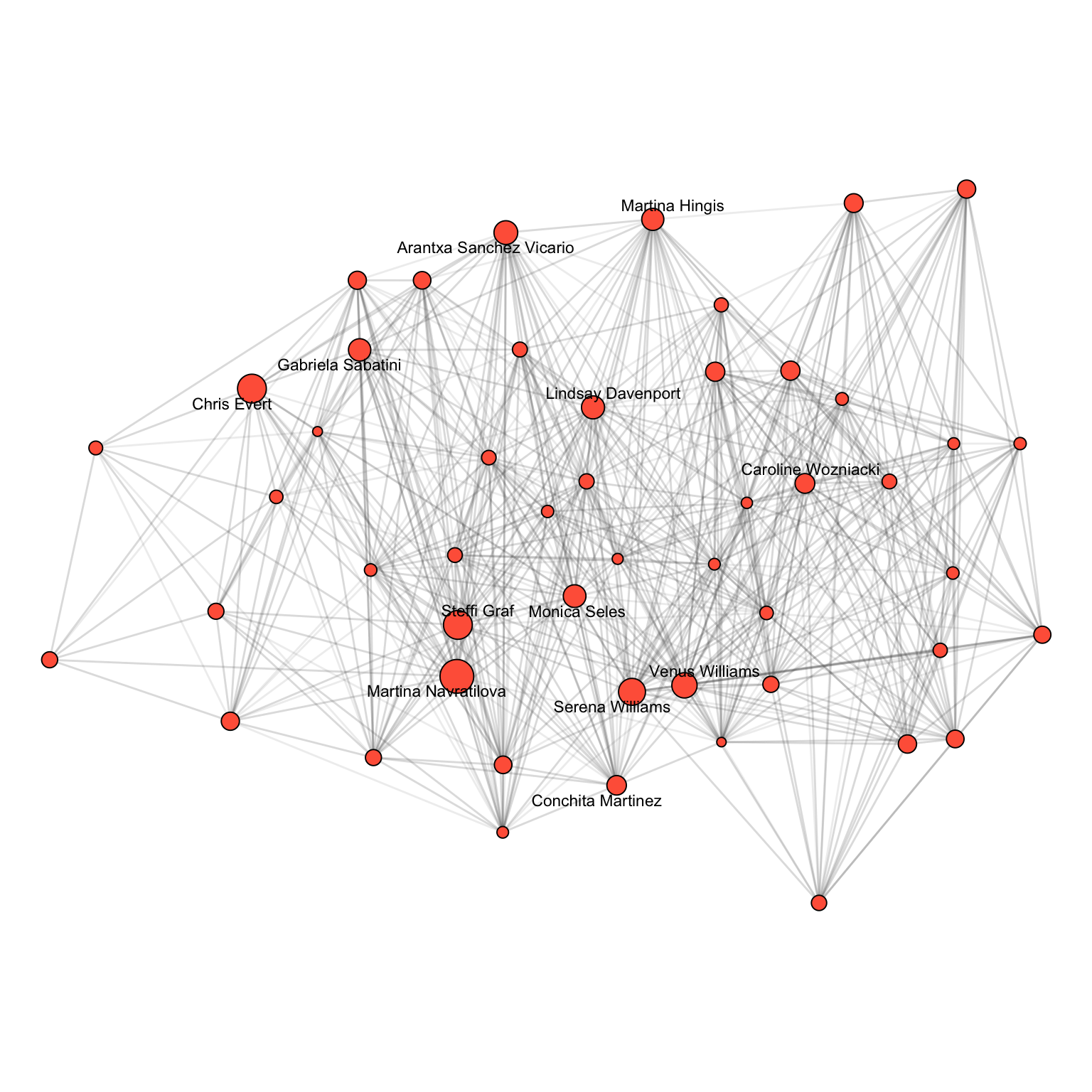
On the men’s tour, Roger Federer leads, followed closely by Jimmy Connors, Novak Djokovic, Rafael Nadal, and Ivan Lendl. The top of the list spans every era from the 1970s onwards, which reflects two properties of PageRank as applied here. Career length matters: Connors and Lendl played long careers with hundreds of high-quality wins. Quality of opposition matters too: the “big three” of Federer, Nadal, and Djokovic each accumulated wins against the dominant players of their respective generations, which is the kind of endorsement PageRank rewards most strongly.
On the women’s tour, Martina Navratilova holds a clear lead, with Chris Evert and Steffi Graf nearly tied for second, followed by Serena and Venus Williams. The same two effects are visible: Navratilova and Evert played remarkably long careers with overlapping peaks, while the Williams sisters earned top-tier endorsements throughout the 2000s and 2010s. PageRank does not separate peak dominance from longevity, since a player who beat strong opponents over fifteen years scores similarly to one who dominated a shorter period. This is not a flaw of the index but a consequence of how endorsement-based ranking works, and it is worth keeping in mind when interpreting the figures as an “all-time” ranking.
4.5 Normalization
Many centrality indices can be normalized to produce values that are comparable across networks of different sizes. For instance, raw degree depends on the number of nodes in the network, making it difficult to compare across networks. Normalized degree divides by the maximum possible degree (\(n - 1\)), yielding a proportion.
degree(dbces11)A B C D E F G H I J K
1 1 2 2 3 4 4 4 4 4 5 degree(dbces11, normalized = TRUE) A B C D E F G H I J K
0.1 0.1 0.2 0.2 0.3 0.4 0.4 0.4 0.4 0.4 0.5
Tip
Normalization is essential when comparing centrality across networks of different sizes. Within a single network, the ranking of nodes is unaffected by normalization, so it only matters when you need scores on a comparable scale.
Most igraph centrality functions accept a normalized argument. For betweenness and closeness, normalization adjusts for both network size and directedness.
4.6 Centralization
While centrality is a node-level property, centralization is a network-level summary that captures how unequal the distribution of centrality is across all nodes. Freeman’s centralization compares the observed network to the theoretical maximum inequality, which occurs in a star graph (one node connected to all others, no other edges).
A centralization score of 1 means the network is maximally centralized (like a star), while a score near 0 means centrality is evenly distributed (like a ring or complete graph). Figure 4.6 shows these two extremes side by side.
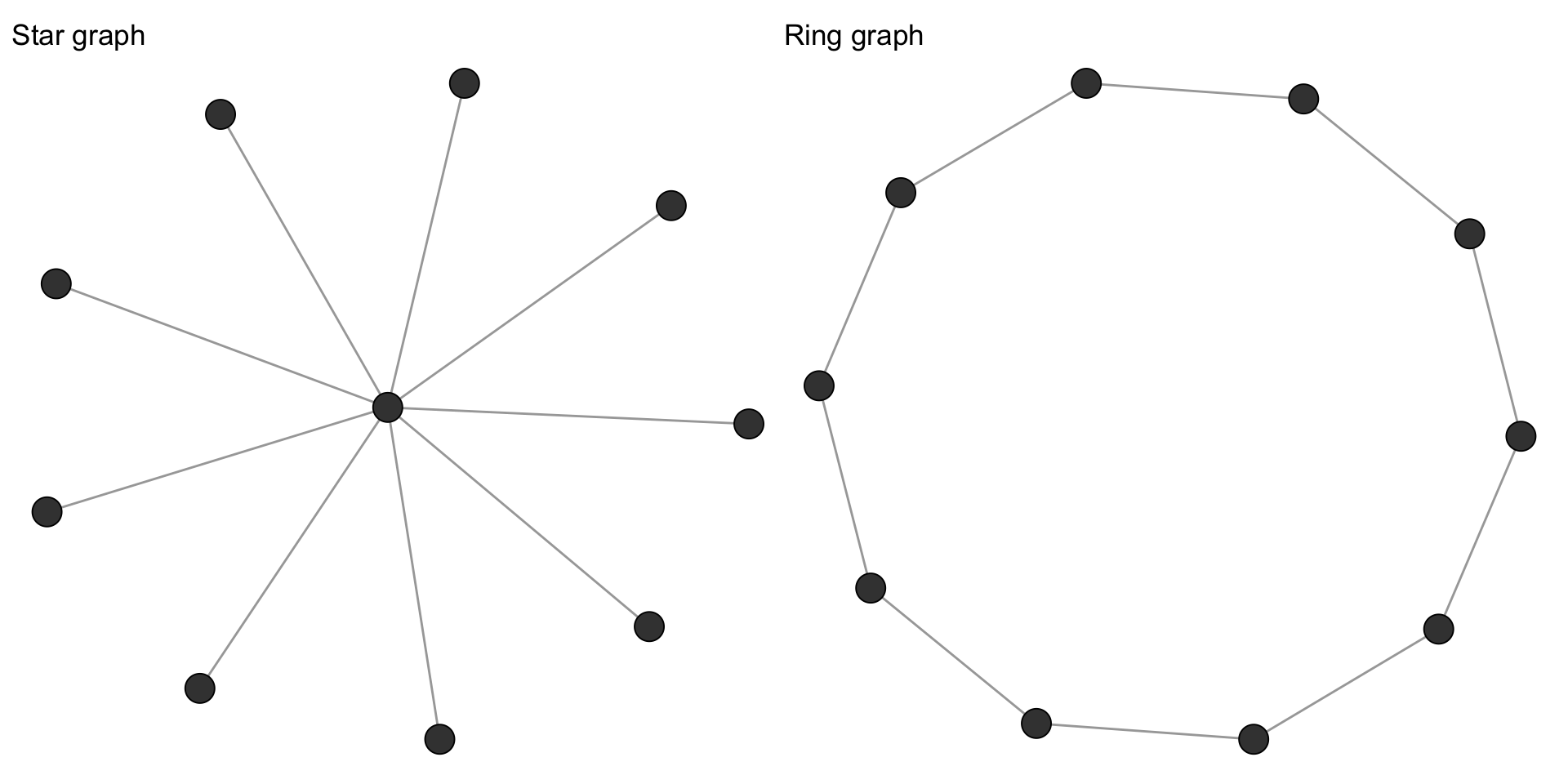
centr_degree(make_star(10, mode = "undirected"))$centralization[1] 0.8centr_degree(make_ring(10))$centralization[1] 0igraph provides centralization functions for degree (centr_degree()), betweenness (centr_betw()), closeness (centr_clo()), and eigenvector centrality (centr_eigen()).
c(
degree = centr_degree(karate)$centralization,
betweenness = centr_betw(karate)$centralization,
closeness = centr_clo(karate)$centralization,
eigen = centr_eigen(karate)$centralization
) degree betweenness closeness eigen
0.3761141 0.4055572 0.2981949 0.6458497 These scores tell us not just who is central, but how centralized the network is as a whole. A highly centralized network depends heavily on a few key nodes, making it potentially vulnerable if those nodes are removed. For the karate club, eigenvector centralization is the highest of the four values, reflecting that prestige concentrates around the instructor and the administrator whose conflict later split the club. Betweenness and degree are moderately centralized, while closeness is the most evenly distributed: in a small, densely connected network, every member is within a few steps of everyone else, so no one dominates on reachability.
4.7 Other Centrality Packages
Beyond igraph, several R packages offer additional centrality indices. The sna package implements indices such as flow betweenness (based on maximum flow rather than shortest paths), information centrality (based on information-theoretic measures), and stress centrality (counting all shortest paths through a node, without normalization). sna functions operate on adjacency matrices rather than igraph objects, so we first convert the graph.
A <- as_adjacency_matrix(dbces11, sparse = FALSE)
sna::flowbet(A, gmode = "graph") [1] 0 0 6 9 14 14 11 22 15 8 31round(sna::infocent(A, gmode = "graph"), 3) [1] 0.587 0.427 0.804 0.656 0.971 1.133 1.117 1.126 1.129 1.105
[11] 1.128
Note
We call sna functions via sna:: rather than attaching the package, because sna defines functions with the same names as igraph (degree(), betweenness(), closeness()) and attaching it would mask the igraph versions we have been using.
The centiserve package provides the largest collection, with over 30 additional indices. Packages like CINNA, influenceR, and keyplayer offer smaller, more specialized selections.
Note
The sheer number of available centrality indices can be overwhelming. More indices does not mean better analysis. It is generally more productive to choose one or two indices that align with your research question than to compute all available options and pick the most favorable result.
4.8 Choosing a Centrality Index
With so many indices available, how should one choose? Borgatti and Everett (2006) argue that the choice should be guided by the type of network flow one implicitly has in mind: Does influence travel along shortest paths, along any walk, by parallel duplication, or only by direct transfer? More pragmatically, the key is to let the research question guide the choice rather than the other way around:
- If you are interested in activity or popularity, degree (or strength for weighted networks) is the natural choice.
- If you care about efficiency of communication or independence, closeness captures how quickly a node can reach others.
- If brokerage or control is your focus, betweenness identifies nodes that bridge different parts of the network.
- If you are interested in influence through connections, eigenvector centrality or PageRank captures prestige by association.
The worst practice is to compute several indices and then selectively report whichever supports the desired narrative. In the best case, you have a substantive argument for why a specific structural property matters, apply the corresponding index, and let the result speak to your hypothesis.
When multiple indices seem equally defensible and you are uncertain which to choose, the approach introduced in Section 4.10 offers a principled alternative: rather than committing to a single index, you can analyze the partial ordering that most indices agree on.
4.9 Use Case: Florentine Families
We return to the Florentine Families marriage network introduced in Chapter 3, popularized in network analysis by Padgett and Ansell (1993), which records marriage ties among prominent Renaissance families in Florence. This network is included in the networkdata package.
data("flo_marriage")The dataset contains one isolated family (the Pucci), who form no marriage ties to the other families. Because closeness is not well-defined for disconnected networks (see the earlier callout), we restrict the analysis to the connected subgraph of the remaining 15 families.
flo_marriage <- subgraph(
flo_marriage,
components(flo_marriage)$membership ==
which.max(components(flo_marriage)$csize)
)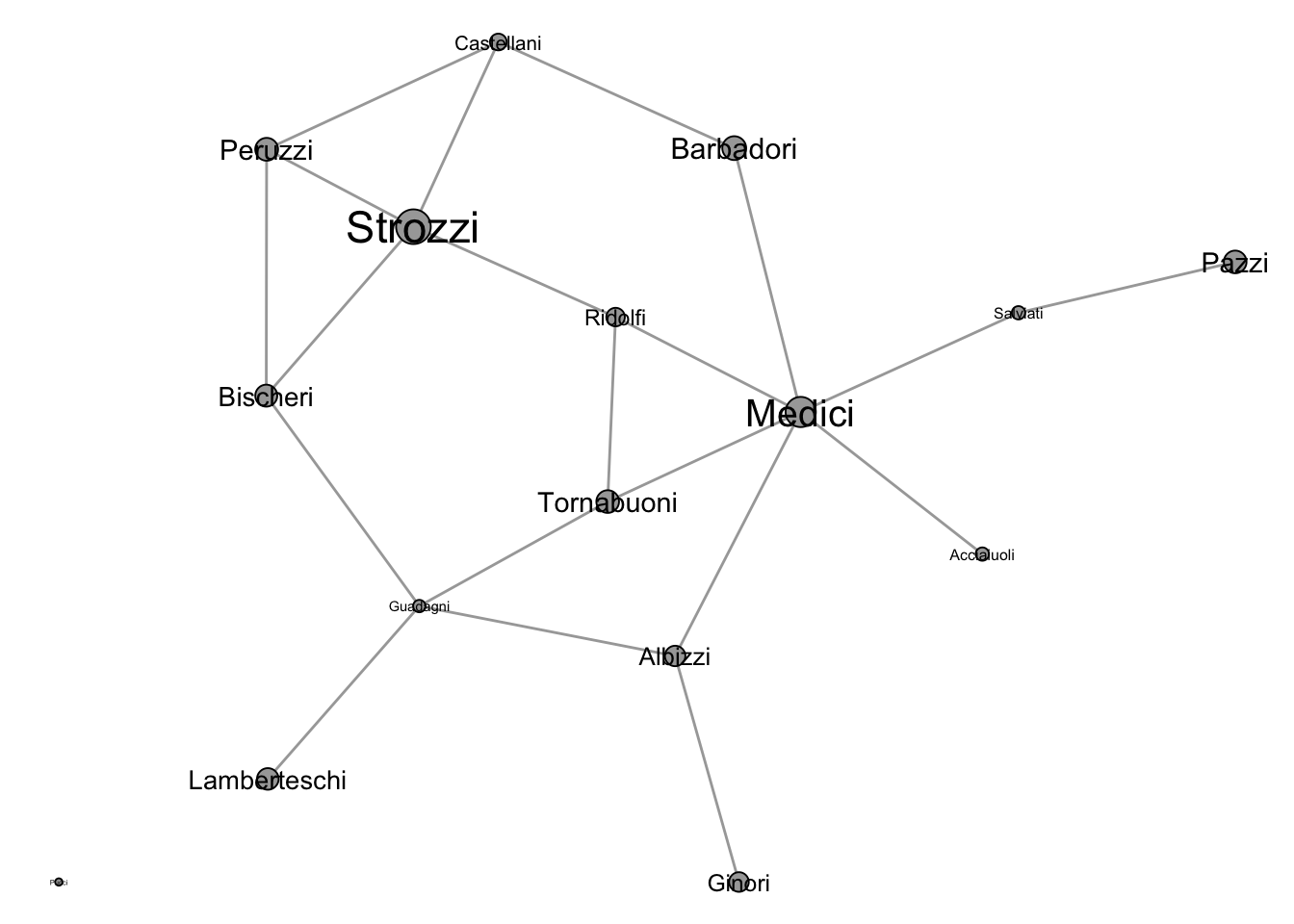
Marriages in Renaissance Florence were strategic alliances designed to improve a family’s political standing and access to resources. The network in Figure 4.7 shows these marriage ties, with node sizes proportional to each family’s wealth. Although the Strozzi were the wealthiest family, it was ultimately the Medici who rose to become the most powerful. A centrality analysis helps explain why.
The table below shows the centrality ranking of each family across the four most commonly used indices (1 = highest rank).
| Family | Degree | Betweenness | Closeness | Eigenvector |
|---|---|---|---|---|
| Acciaiuoli | 13.5 | 13.5 | 11.5 | 12 |
| Albizzi | 6.5 | 3.0 | 3.5 | 9 |
| Barbadori | 10.5 | 8.0 | 6.5 | 10 |
| Bischeri | 6.5 | 6.0 | 8.0 | 6 |
| Castellani | 6.5 | 10.0 | 9.5 | 8 |
| Ginori | 13.5 | 13.5 | 13.0 | 14 |
| Guadagni | 2.5 | 2.0 | 5.0 | 5 |
| Lamberteschi | 13.5 | 13.5 | 14.0 | 13 |
| Medici | 1.0 | 1.0 | 1.0 | 1 |
| Pazzi | 13.5 | 13.5 | 15.0 | 15 |
| Peruzzi | 6.5 | 11.0 | 11.5 | 7 |
| Ridolfi | 6.5 | 5.0 | 2.0 | 3 |
| Salviati | 10.5 | 4.0 | 9.5 | 11 |
| Strozzi | 2.5 | 7.0 | 6.5 | 2 |
| Tornabuoni | 6.5 | 9.0 | 3.5 | 4 |
The Medici rank first (or nearly first) on every index. Their high degree means they had the most marriage ties, making them the most active family in forming alliances. Their top betweenness ranking reveals that they occupied a critical brokerage position: many of the shortest paths between other families passed through them, giving the Medici control over the flow of information and political favors. Their high closeness means they could reach any other family through fewer intermediaries than anyone else. And their eigenvector centrality shows that they were not just well-connected, but connected to other well-connected families.
The Strozzi, despite their wealth, were structurally peripheral. Their marriage ties connected them to less central families, limiting their ability to broker relationships or influence the network as a whole. This case illustrates a key insight of network analysis: structural position can matter more than individual attributes like wealth.
We can also examine centralization to characterize the network as a whole.
c(
degree = centr_degree(flo_marriage)$centralization,
betweenness = centr_betw(flo_marriage)$centralization,
closeness = centr_clo(flo_marriage)$centralization,
eigen = centr_eigen(flo_marriage)$centralization
) degree betweenness closeness eigen
0.2380952 0.4368132 0.3224523 0.5277086 Eigenvector centralization is the largest, reflecting that prestige in this network is concentrated in a tightly connected core around the Medici. Betweenness centralization is also high and confirms that brokerage was in the hands of a few families. Degree and closeness are more evenly spread, which fits the intuition that several families were reasonably active and well-positioned even if none were as dominant as the Medici on a structural measure.
4.10 Beyond a Single Index
We have now seen that different centrality indices can pick different “most central” nodes on the same network, and that their correlations depend on the network itself. A natural question follows: is there any structural property that all common indices respect, and if so, can we use it to reason about rankings without committing to a single index? The netrankr package is built around exactly this idea, which is developed formally in Schoch and Brandes (2016).
4.10.1 Neighborhood Inclusion
The structural property at the heart of netrankr is neighborhood inclusion, illustrated in Figure 4.8. If every neighbor of a node \(u\) is also a neighbor of another node \(v\) (plus possibly \(v\) itself), then \(u\) sits in a structurally weaker position than \(v\): whatever \(u\) can reach, \(v\) can reach too, and more. Every commonly used centrality index respects this: if \(u\) is neighborhood-dominated by \(v\), no index will rank \(u\) above \(v\).
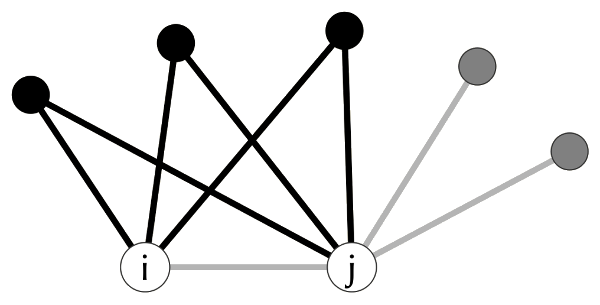
The function neighborhood_inclusion() returns a matrix P where P[u, v] = 1 whenever \(u\) is dominated by \(v\). The helper comparable_pairs() reports what fraction of node pairs the partial order actually orders.
P <- neighborhood_inclusion(dbces11)
comparable_pairs(P)[1] 0.1636364Only about 16% of pairs are comparable in dbces11. The other 84% are structurally ambiguous, and that ambiguity is exactly the room in which different indices can disagree. In a network where every pair is comparable, all indices would produce the same ranking.
4.10.2 Rank Intervals
For a partially ordered set of nodes, every centrality index is one particular linear extension, a total ordering that respects the partial order. rank_intervals() reports, for each node, the smallest and largest rank it can take across all such extensions. Wide intervals mean the structure leaves the node’s position open; narrow intervals mean the structure pins it down.
rk_int <- rank_intervals(P)
rk_int node:A rank interval: [1, 6]
node:B rank interval: [1, 9]
node:C rank interval: [2, 9]
node:D rank interval: [2, 11]
node:E rank interval: [3, 11]
node:F rank interval: [2, 11]
node:G rank interval: [2, 11]
node:H rank interval: [2, 11]
node:I rank interval: [1, 11]
node:J rank interval: [1, 11]
node:K rank interval: [3, 11]We can overlay the ranks that specific indices assign to each node on top of these intervals. The three continuous-valued indices are rounded to four decimals so that floating-point near-ties collapse into a single rank rather than plotting as two barely-distinguishable points.
cent_scores <- data.frame(
degree = degree(dbces11),
betweenness = round(betweenness(dbces11), 4),
closeness = round(closeness(dbces11), 4),
eigenvector = round(eigen_centrality(dbces11)$vector, 4)
)
plot(rk_int, cent_scores = cent_scores)In Figure 4.9 the four indices land at different rank positions within each node’s interval, which is the partial-ordering view of the disagreement we saw earlier in Figure 4.2.
Note
Occasionally a betweenness point falls outside a node’s interval. Betweenness is the one common index that does not strictly preserve neighborhood inclusion. Two nodes can satisfy \(N(u) \subseteq N[v]\) yet receive equal betweenness scores. All other standard indices are strictly order-preserving.
4.10.3 Exact Rank Probabilities
Rather than picking one index, we can enumerate every linear extension of the partial order and ask, for each node, how often it lands at each rank. For small graphs, exact_rank_prob() does this exhaustively.
res <- exact_rank_prob(P)The probability of being the most central node (top rank) is the last column of res$rank.prob.
round(res$rank.prob[, ncol(res$rank.prob)], 2) A B C D E F G H I J K
0.00 0.00 0.00 0.14 0.16 0.11 0.11 0.14 0.09 0.09 0.16 Nodes E and K share the highest probability (0.16) of occupying the top rank across all valid rankings, closely followed by D and H. The expected rank, the weighted average of a node’s rank over all extensions, gives a single summary.
round(res$expected.rank, 2) A B C D E F G H I J K
1.71 3.00 4.29 7.50 8.14 6.86 6.86 7.50 6.00 6.00 8.14 This is a more nuanced picture than any single index provides. Earlier we saw that degree, betweenness, closeness, eigenvector, and subgraph centrality each crowned a different node. The probabilistic view says some of those nodes (like E) are plausibly central across many valid rankings, while the picks of individual indices reflect one extension among many.
These tools are most useful when the choice of index is contested or arbitrary, and when the graph is small enough for the exhaustive enumeration to run. On larger networks, exact_rank_prob() becomes infeasible, but neighborhood_inclusion() and rank_intervals() remain cheap and still reveal which rankings the structure forces and which it leaves open.
References
Bonacich, Phillip. 1987. “Power and Centrality: A Family of Measures.” American Journal of Sociology 92 (5): 1170–82.
Borgatti, Stephen P, and Martin G Everett. 2006. “A Graph-Theoretic Perspective on Centrality.” Social Networks 28 (4): 466–84.
Brin, Sergey, and Lawrence Page. 1998. “The Anatomy of a Large-Scale Hypertextual Web Search Engine.” Computer Networks and ISDN Systems 30 (1–7): 107–17.
Estrada, Ernesto, and Juan A Rodriguez-Velazquez. 2005. “Subgraph Centrality in Complex Networks.” Physical Review E 71 (5): 056103.
Freeman, Linton C. 1979. “Centrality in Social Networks Conceptual Clarification.” Social Networks 1 (3): 215–39.
Padgett, John F, and Christopher K Ansell. 1993. “Robust Action and the Rise of the Medici, 1400–1434.” American Journal of Sociology 98 (6): 1259–319.
Schoch, David, and Ulrik Brandes. 2016. “Re-Conceptualizing Centrality in Social Networks.” European Journal of Applied Mathematics 27 (6): 971–85.